Solving the
human context
window problem.
Everyone's obsessed with the LLM's context window.
The real bottleneck is yours.
npx <coming soon> init●local-first ● your data stays in your repo
You, every week.
Probably.
Notepad files. Sticky notes. Screenshots in folders you named badly. The terminal that crashed yesterday took half of it with it. Your brain, trying to hold all of this. At once.
The AI's memory is
getting better every month.
Yours isn't.
Nine pains. Nine answers.
The problems and time sinks I had every day while vibecoding. ADHDev exists because I got tired of all of them. And I assume some of you are too.
Human context windows are the real bottleneck.
Everyone is optimizing the LLM's. Bigger ones, smarter compaction, better memory tools. Nobody is optimizing yours. Especially if you have ADHD — parallel thinking, scattered thoughts, dropped threads.
→A board, a brain dump, and an activity feed that hold what your brain drops between sessions.
Your workflow is scattered everywhere.
Lists in your head. Bugs in notepad. Decisions in DMs. Screenshots on your desktop. The terminal that crashed yesterday took half of it with it.
→One board per project. Tickets, comments, attachments, terminal output — all in one place that survives every reload.
Sequencing matters more than people admit.
Running tickets in the order you remember them wastes tokens, breaks dependencies, causes regressions, and forces the AI to backwards-guess from code.
→The agent plans the sequence — grouping related tickets, respecting dependencies, batching for shared context. You accept the shape, it runs in the right order.
The AI forgets what it did and why.
When a ticket reopens, the agent starts fresh and reconstructs context from code. The original reasoning, the constraint, the failed approach — all gone.
→Full chronology per ticket. Receipts feed forward as seed context for the next run. The board remembers what you don't.
Managing the board shouldn't be its own job.
Statuses go stale. Priorities drift. Tags rot. Tickets get miscategorized. Duplicates pile up. Links break. Reopens get lost. The meta-layer becomes a chore that defeats the point of having a board.
→The agent that works on tickets also keeps the board clean. Statuses updated, priorities re-ranked, tags and categories applied, duplicates merged, links maintained, reopens tracked. You stop being the meta-layer.
Feedback scatters across DMs, chats, and your head.
You spot a bug in Slack. Screenshot it to your desktop. Half-remember it next week. The AI never sees the context where you saw the problem.
→One thread per ticket. Drop comments and screenshots where the work is. The agent reads them on the next run.
Working naturally shouldn't be friction.
Pasting screenshots, attaching files, switching from thinking-out-loud to building — these basic moves shouldn't require ceremony.
→Ctrl+V to paste anywhere. Drag-drop files. Discuss mode to plan, Execute mode to ship. Same context flows through both.
Some calls are only yours to make.
Your AI will confidently say “done.” Sometimes it is. Sometimes it isn't, and you find out three days later when something breaks.
→The agent moves tickets to For Review. Only you move them to Closed. Structural, not a best practice — enforced at the API.
You keep working while the AI keeps working.
Most agent tooling is a relay. AI works, you wait. You work, AI waits. That defeats the point of running an agent in the first place.
→While the AI runs a batch, you queue tickets, sign receipts, leave feedback, drop brain-dump thoughts. The board manages itself.
// what ADHDev is
A tool for
human + agent
shared context.
Functionally: a PM tool for your AI agents. Kanban-style. Local-first. Runs alongside Claude Code, Codex, Gemini or any CLI agent. Your data stays in your project folder.
The point isn't to replace your agent. It's to give you and your agent a shared place to work — a board that holds the context both of you keep dropping.
What it actually looks like.
Live screenshots from the app. Pick a surface — the board, the terminal, brain dump, agent receipts, batch planning, activity feed — and see what it actually does.
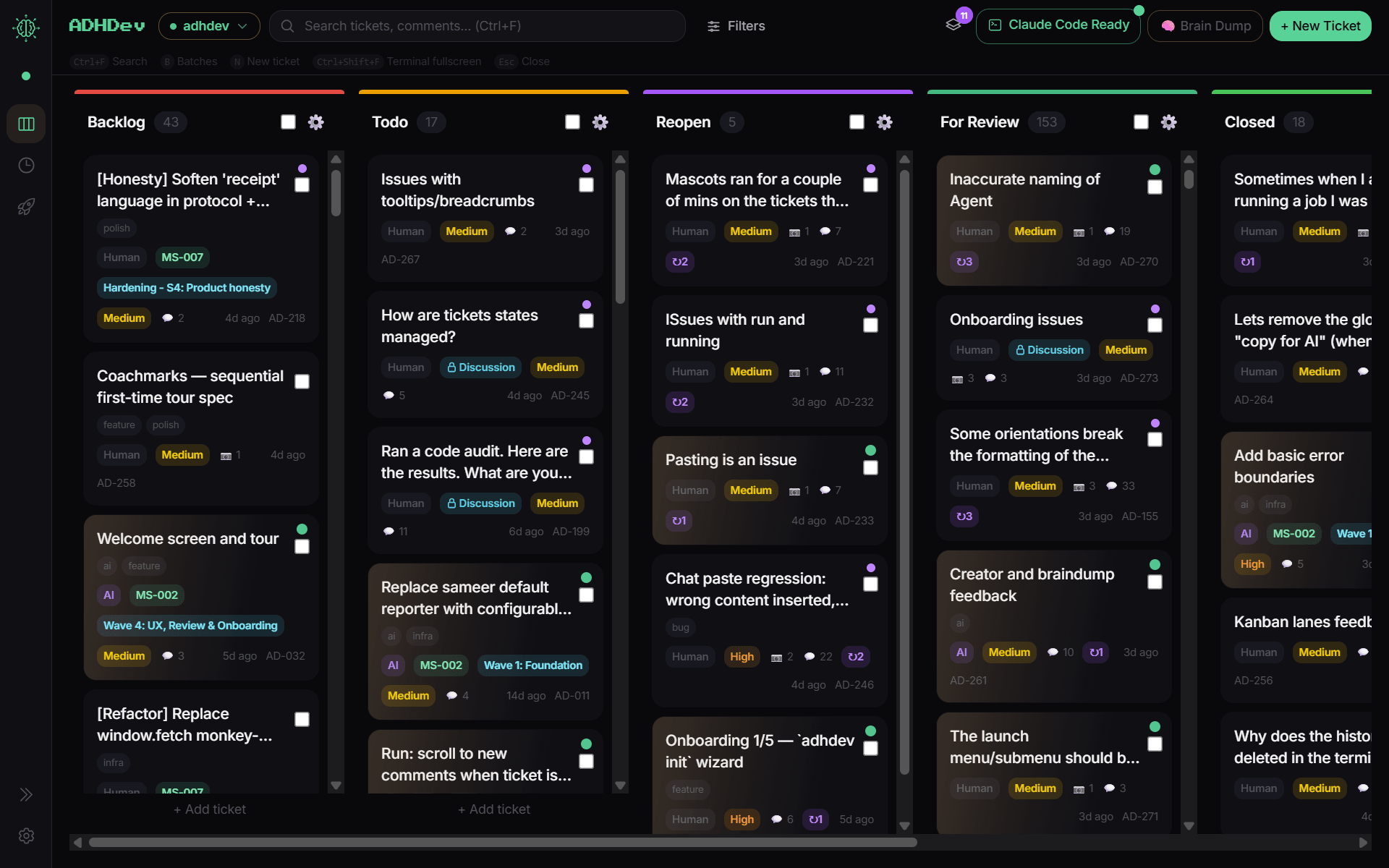
// the board
Five columns. Three of them are the trust model.
Backlog, Todo, Reopen, For Review, Closed. Tickets carry their own IDs (AD-218, MS-002…), their wave/batch tags, an AI/human pill. The agent can promote to For Review. Only you can close.
Every feature in v1.
Who this is for.
And who it's not.
- ✓You're a product person, designer, founder, consultant, indie hacker — or an engineer who builds more by talking to AI than by writing code yourself
- ✓Your brain drops threads, loses tabs, forgets context, or notices the AI getting sloppy on long sessions
- ✓You want your AI's work to be held, not hoped for
- ✓You love vibecoding on CLI but yearn for a better UX
- ✕You're running 10 AI agents in parallel with git worktreesparallel multi-agent isn't on the roadmap — supervision is the primitive we're building, not speed. one agent you can trust beats five going fast.
- ✕You read every line of AI-generated code before shippingyou're already doing the verification work this product exists to make trustable. it'd feel over-scaffolded for you.
- ✕You need enterprise SSO, audit logs, or compliance features todaynot yet. focused on individual builders and small teams first; enterprise governance comes later.
// why this exists
Three months ago, I got bitten by the vibecoding bug. It was one of those holy-shit, once-a-decade moments.
Week 1, the only limit was my imagination. I shipped things I'd wanted for years in single afternoons. I went to bed grinning. My wife asked what I was building; I couldn't explain it without spiraling into how the whole world had just changed.
Week 2, the cracks. Week 3, the wall. By week 4, I'd traded one kind of hard for another. The code part was fast. The everything-around-the-code part was duct tape.
I was keeping bug notes in .txt files I'd lose track of. Lining up prompts in Notepad to paste into the terminal, only to find half the prompt clipped off. Saving screenshots into folders with names I couldn't reconstruct, then over-explaining to the agent which file to look at. Convincing the agent of things it had changed yesterday — only for it to draw blanks. Coming back the next morning and not remembering what I'd asked it to do the night before.
The worst part: sometimes “done” wasn't done. The agent would mark a ticket complete, write a clean-sounding summary, and I'd find out three days later that the feature was subtly broken. I was rubber-stamping its work because actually verifying it required a git fluency and an attention span I didn't have.
I'm not an engineer. I have ADHD. Parallel thinking, scattered thoughts, dropped threads — not a deficit, just a different shape that needs holding. The sheer volume of ideas, rate of iteration made it worse. For months, the workflow was chaos. My brain was the bottleneck.
The realization came slower. Vibecoding didn't kill the need for project management — it made it more necessary. The work rhythm changed: load up the task prompts, pass them to the agent to execute, fill the 5–20 minute wait with something — think, review, doom-scroll, dream up five new ideas — or switch over to another task (or project), then snap back when the agent is done. Context hazy, headspace fuzzy.
Everyone in the AI coding world is talking about the LLM's context window. Bigger ones. Smarter compaction. Better memory tools. All of that matters. But the context window that's actually overflowing in my workflow isn't the AI's. It's mine.
Speed had stopped being the problem. Direction, supervision, and verification were. Did the AI build what I'd intended? Half the time it said yes. In a new session it'd say no. The whole thing was fickle.
I built ADHDev to help me make sense of the madness and context overload. It was a board that was managed and maintained by any AI that is assigned to work on it. Tickets hold the work — notes, screenshots (paste with Ctrl+V, anywhere), files, half-thoughts, the things I'd otherwise lose by Tuesday. I can switch between brainstorming (no changes to code allowed) and execution mode. Ask it to plan a batch and it groups your tickets optimally to minimize module rework and token spend. The agent picks them up, runs with full context, streams output back into the ticket, and leaves a receipt when it's done: files touched, commands run, what it claims to have verified. Crash the terminal, close the laptop, come back tomorrow — the work stays where you left it.
I'm putting this out there for builders who might be facing the same problems. If it helps you the way it helped me, tell me. If it doesn't, still tell me.
— Sameer
Get in before
the first 500.
You'll get the download link before public launch. I'll email you maybe twice. Maybe three if there's a real reason. Not a newsletter.
